Education
University of Maryland, College Park, Maryland
September 2014 - December 2019
MS + PhD, Electrical and Computer Engineering.
Advisor: Rama Chellappa
|
Indian Institute of Technology, Kharagpur, India
July 2009 - May 2014
B. Tech (Hons) and MTech, Electronics and Communication Engineering
Minor: Computer Science and Engineering
|
Professional Experience
Apple
Staff Research Scientist
August 2025 - Present
|
Meta (previously Facebook Inc)
Research Scientist
Feb 2020 - July 2025
|
Snap Research Inc, NY
Research Intern
June 2018 – August 2018
|
IBM T.J. Watson Research Centre, Yorktown Heights, NY
Research Intern
June 2017 – August 2017
|
Other Professional Activities
Reviewer
IEEE Signal Processing Society and Computer Society (August 2018 - Present)
- IEEE Transactions of Neural Networks and Learning Systems
- IEEE Signal Processing Letters
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Image Processing
- Springer International Journal of Computer Vision
- ICCV'19-23
- CVPR'20-24
- ECCV'20-24
- AAAI-2022
- NeurIPS 2021-2023
|
|
Research
I'm interested in computer vision, deep learning, generative AI, and image processing. Most of my research has been about human centric computer vision, ranging from 3D generation of avatars to modeling and personalizing behaviors of these avatars. Recently I have started diving deep into personalization of these avatars given user prompts. I have successfully applied my built techniques into other problems like vehicles reidentification anf 3D facial reconstruction and AI avatars. Some publications are listed below.
|
|
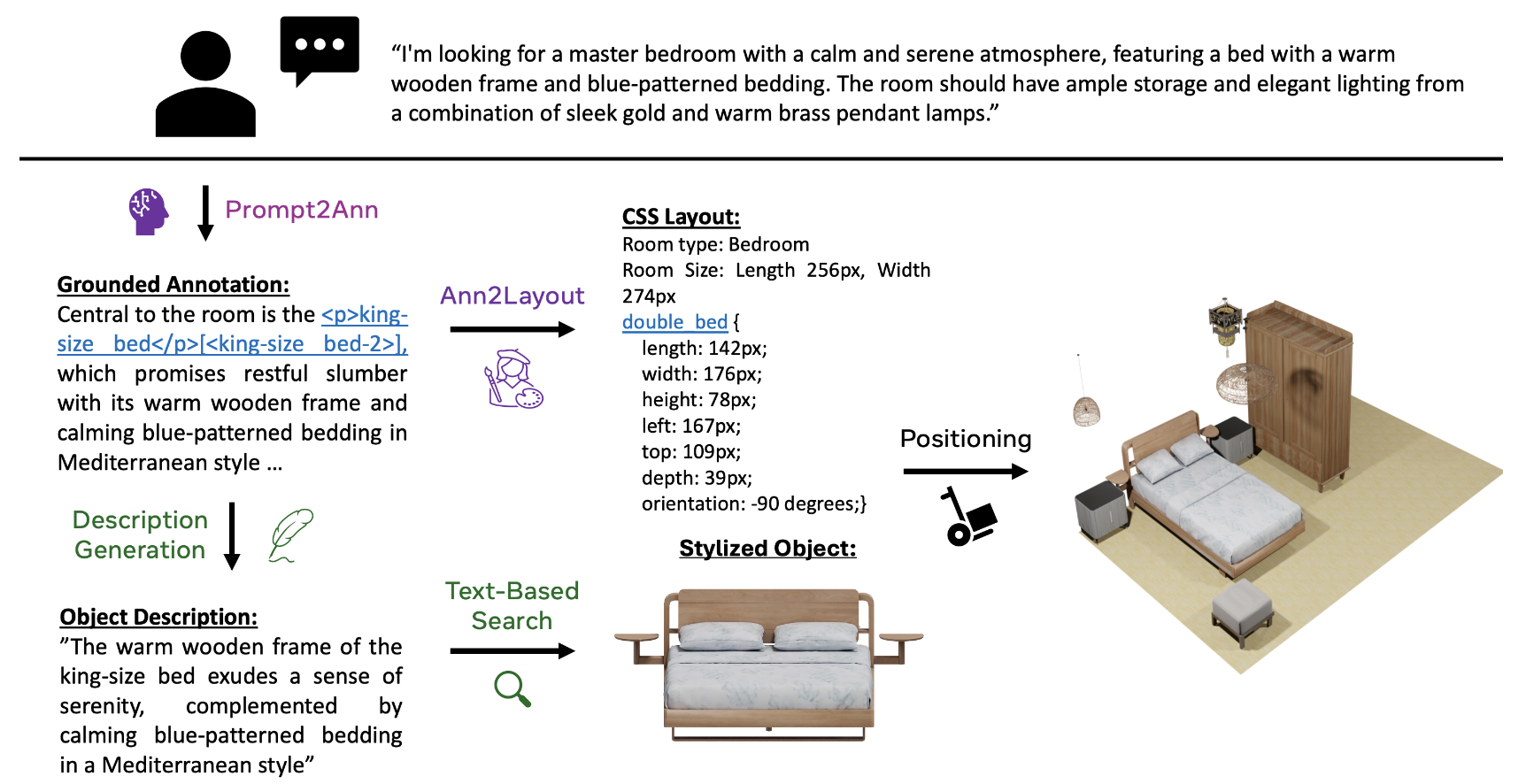
Decorum: A Language-Based Approach For Style-Conditioned Synthesis of Indoor 3D Scenes
Kelly Marshall,
Omid Poursaeed,
Sergiu Oprea,
Amit Kumar,
Anushrut Jignasu
Chinmay Hegde,
Yilei Li,
Rakesh Ranjan,
(Under submission), 2024
/
arXiv
Decorum enables users to control the scene generation process with natural language by adopting
language-based representations at each stage. This enables us to harness recent advancements in
Large Language Models (LLMs) to model language-to-language mappings.
|
|
|
TalkinNeRF: Animatable Neural Fields for Full-Body Talking Humans
Aggelina Chatziagapi,
Bindita Chaudhury,
Amit Kumar,
Rakesh Ranjan,
Dimitris Samaras,
Nikolaos Sarafianos
ECCV, 2024
/
arXiv
TalkinNeRF is a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result.
|
|
|
AVFace: Towards Detailed Audio-Visual 4D Face Reconstruction
Aggelina Chatziagapi,
Dimitris Samaras,
CVPR, 2023
/
arXiv
AVFace incorporates both modalities (audio and video) and accurately reconstructs the 4D facial and lip motion of any speaker, without requiring any 3D ground truth for training.
|
|
|
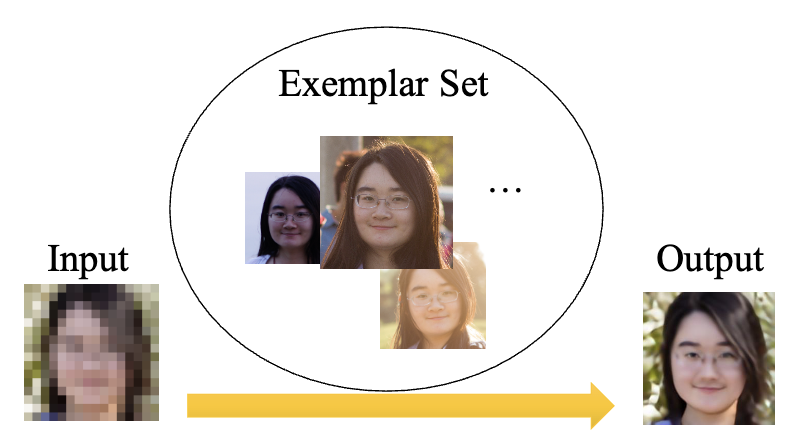
HIME: Efficient Headshot Image Super-Resolution with Multiple Exemplars
Xiaoyu Xiang,
Jon Morton,
Fitsum Reda,
Lucas D Young,
Federico Perazzi,
Rakesh Ranjan,
Amit Kumar,
Andrea Colaco,
Jon P Allenbach
WACV, 2024
/
arXiv
It is challenging to make the best use of multiple exemplars: the quality and alignment of each exemplar cannot be guaranteed. Using low-quality and mismatched images as references will impair the output results. To overcome these issues, we propose the efficient Headshot Image Super-Resolution with Multiple Exemplars network (HIME) method.
|
|
|
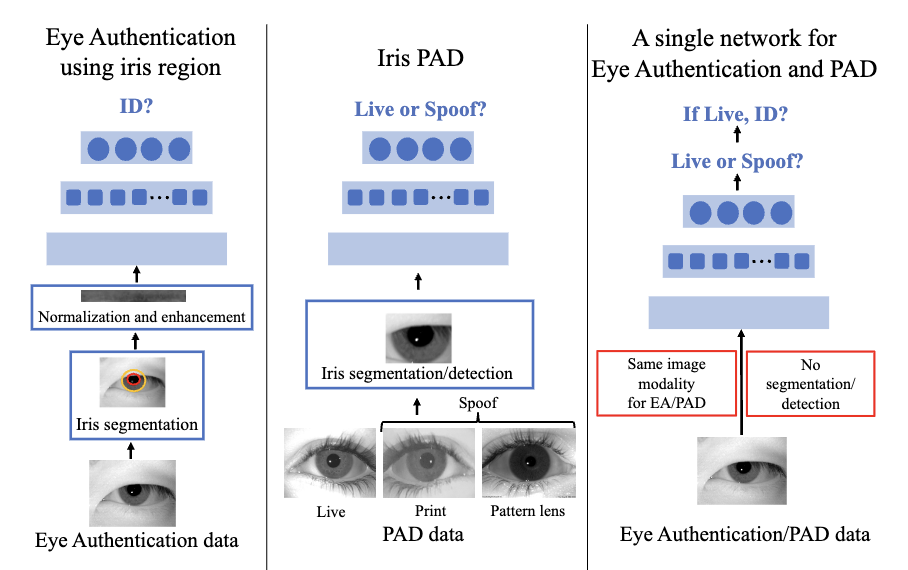
EyePAD++: A Distillation-based approach for joint Eye Authentication and Presentation Attack Detection
using Periocular Images
Prithviraj Dhar,
Amit Kumar,
Kirsten Kaplan,
Khushi Gupta,
Rakesh Ranjan,
Rama Chellappa,
CVPR, 2022
/
arxiv
We propose Eye Authentication
with PAD (EyePAD), a distillation-based method that trains
a single network for EA and PAD while reducing the effect
of forgetting.
|
|
|
EVRNet: Efficient Video Restoration on Edge Devices
Sachin Mehta,
Amit Kumar,
Fitsum Reda,
Varun Nasery,
Vikram Mulukutla,
Rakesh Ranjan,
Vikas Chandra,
ACM-MM, 2021
/
arxiv
To restore
videos on recipient edge devices in real-time, we introduce an efficient video restoration network, EVRNet. EVRNet efficiently allocates parameters inside the network using alignment, differential, and fusion modules.
|
|
|
Integrating Acting, Planning, andLearning in Hierarchical Operational Models
Sunandita Patra,
James Mason,
Amit Kumar,
Malik Ghallab,
Paolo Traverso,
Dana Nau,
ICAPS, 2020
/
arxiv
RAE uses hierarchical operational models to perform tasks in dynamically changing environments.
|
|
|
Semi-Supervised Landmark-Guided Restoration of
Atmospheric Turbulent Images
Samuel Chun Pong Lau,
Amit Kumar,
Rama Chellappa,
IEEE Journal of Selected Topics in Signal Processing (JSTSP), 2021, 2020
/
IEEE
A semisupervised method for jointly extracting facial landmarks and restoring the degraded images by exploiting the semantic information from the landmarks.
|
|
|
S2LD: Semi-Supervised Landmark Detection in Low Resolution Images
and Impact on Face Verification
Amit Kumar,
Rama Chellappa,
CVPR-W, 2020
/
arxiv
Predicting landmarks
directly on low resolution images is more effective than the
current practice of aligning images after rescaling or super-resolution.
|
|
|
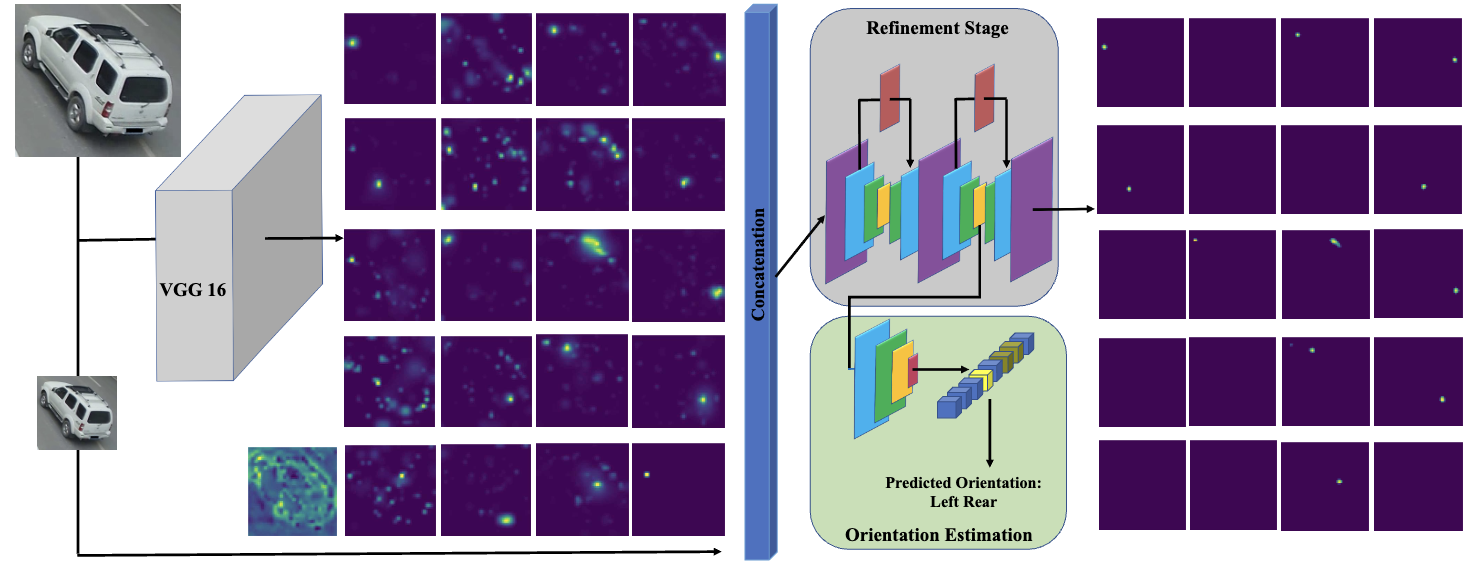
Attention Driven Vehicle Re-identification and Unsupervised Anomaly Detection
for Traffic Understanding
Pirazh Khorramshahi,
Neehar Peri,
Amit Kumar,
Anshul Shah,
Rama Chellappa,
CVPR Nvidia City Challenge (Oral), 2019
/
arxiv
We leverage an attention-based model
which learns to focus on different parts of a vehicle by conditioning the feature maps on visible key-points. We use
triplet embedding to reduce the dimensionality of the features obtained from the ensemble of networks trained using different datasets.
|
|
|
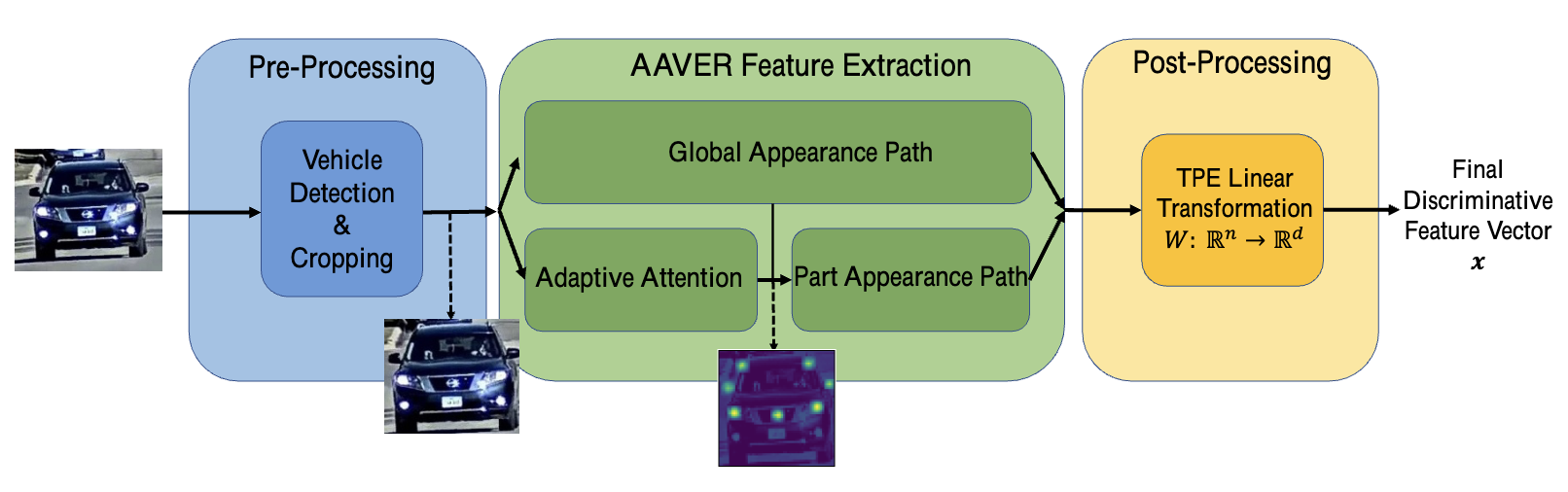
A Dual-Path Model With Adaptive Attention For Vehicle Re-Identification
Pirazh Khorramshahi,
Amit Kumar,
Neehar Peri,
Sai Saketh Rambhatla,
Jun-Cheng Chen,
Rama Chellappa,
ICCV (Oral), 2020
/
arxiv
In AAVER, the global appearance path captures macroscopic vehicle features while the
orientation conditioned part appearance path learns to capture localized discriminative features by focusing attention
on the most informative key-points.
|
|
|
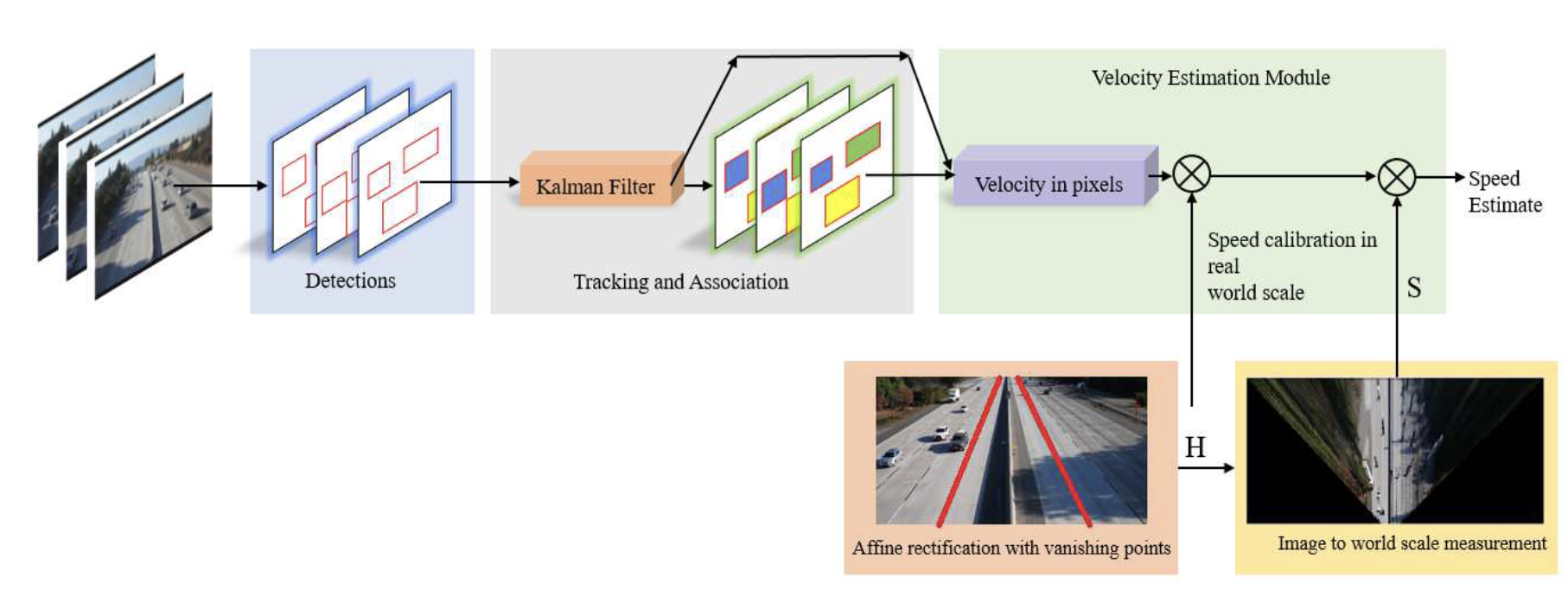
A Semi-Automatic 2D solution for
Vehicle Speed Estimation from Monocular Videos
Amit Kumar,
Pirazh Khorramshahi,
Wei-An Lin,
Prithviraj Dhar,
Jun-Cheng Chen,
Rama Chellappa,
CVPR Nvidia AI City Challenge (Oral), 2018
/
arxiv
We propose a simple two-stage algorithm to approximate the transformation.
Images are first rectified to restore affine properties, then the
scaling factor is compensated for each scene.
|
|
|
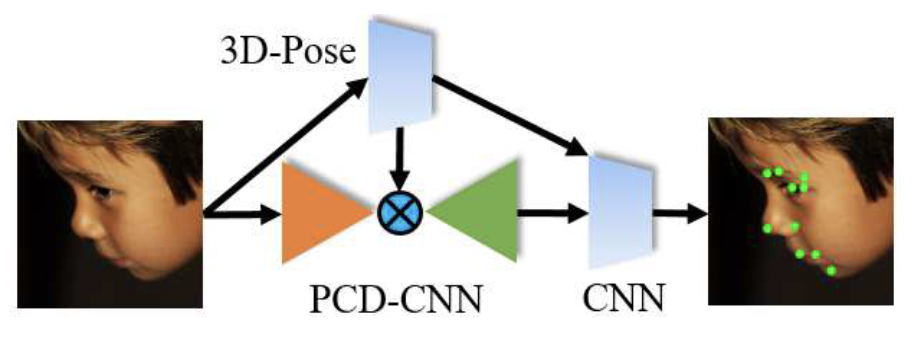
Disentangling 3D Pose in A Dendritic CNN
for Unconstrained 2D Face Alignment
Amit Kumar,
Rama Chellappa,
CVPR, 2018
/
CVPR
Following a Bayesian formulation, we disentangle the 3D pose of a face image explicitly by conditioning the landmark estimation on pose, making it different from multi-tasking approaches.
|
|
|
KEPLER: Simultaneous estimation of keypoints and 3D pose of unconstrained faces in a unified framework by learning efficient H-CNN regressors
Amit Kumar,
Azadeh Alavi,
Rama Chellappa,
Elsevier Image and Vision Computing, 2018
/
arxiv
We present a novel architecture called H-CNN (Heatmap-CNN) acting on an N-dimensional input image which captures informative structured global and local features and thus favors accurate keypoint detecion in in-the wild face images.
|
|
|
KEPLER: Keypoint and Pose Estimation of Unconstrained Faces by Learning Efficient H-CNN Regressors
Amit Kumar,
Azadeh Alavi,
Rama Chellappa,
FG, 2017
/
arxiv
Although a simple feed forward neural network can learn the mapping between input and output spaces, it cannot learn the inherent structural dependencies. We present a novel architecture called H-CNN (Heatmap-CNN) which captures structured global and local features and thus favors accurate keypoint detecion.
|
|
|
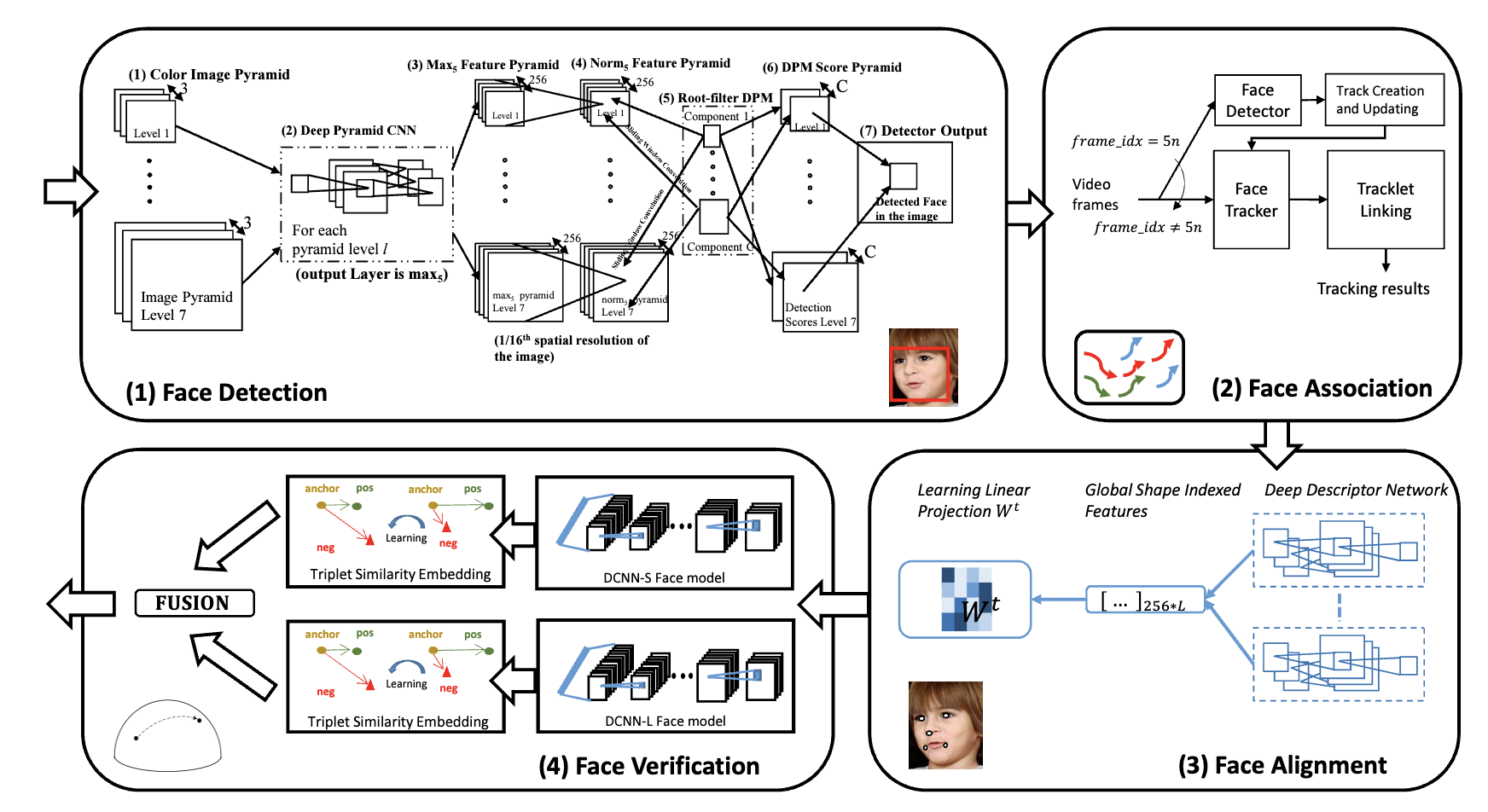
Unconstrained Still/Video-Based Face Verification with Deep Convolutional Neural Networks
Jun-Cheng Chen,
Rajeev Ranjan,
Swami Sankaranarayanan,
Amit Kumar,
Ching-Hui Chen,
Vishal M. Patel,
Carlos D. Castillo,
Rama Chellappa,
IJCV, 2017
/
arxiv
First Deep Learning based face verification system.
|
|
|
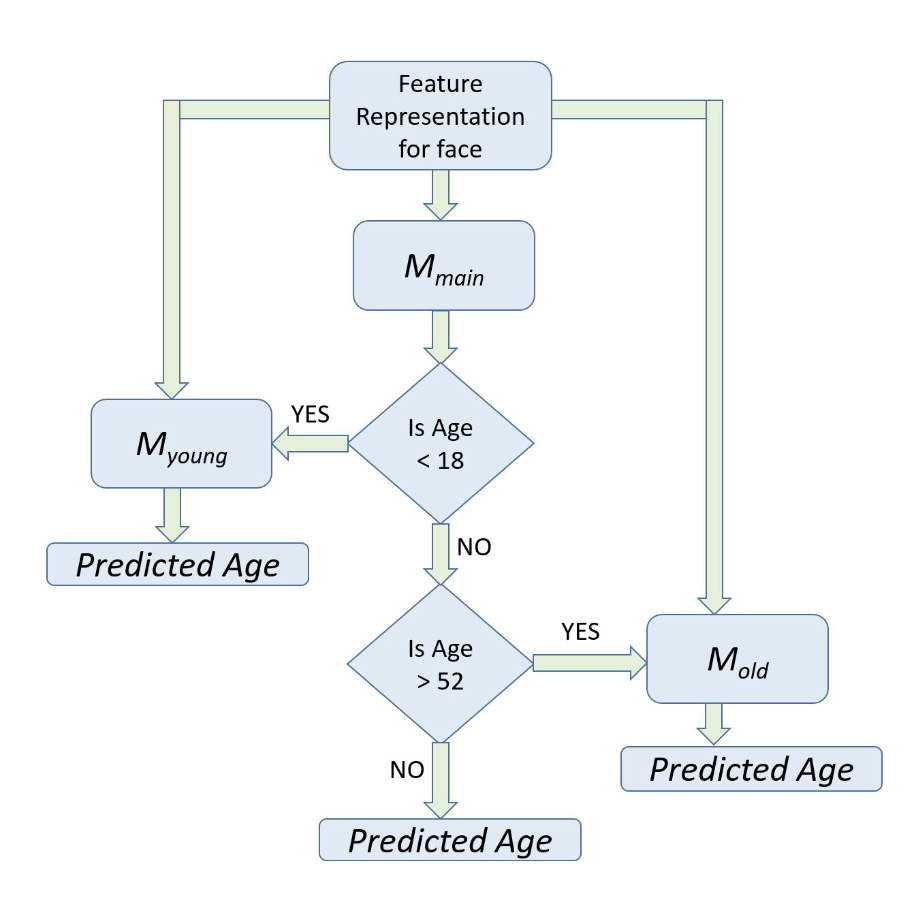
A Cascaded Convolutional Neural Network for Age Estimation
of Unconstrained Faces
Jun-Cheng Chen,
Amit Kumar,
Rajeev Ranjan,
Vishal M. Patel,
Azadeh Alavi,
Rama Chellappa,
BTAS, 2016
/
arxiv
A coarse-to-fine approach for estimating the
apparent age from unconstrained face images using deep
convolutional neural networks (DCNNs). Also one of the first models in the Deep learning era
|
|
|
Towards the Design of an End-to-End Automated
System for Image and Video-based Recognition
Rama Chellappa,
Jun-Cheng Chen,
Rajeev Ranjan,
Swami Sankaranarayanan,
Amit Kumar,
Vishal M. Patel,
Carlos D. Castillo,
IEEE Information Theory and Applications, 2016
/
arxiv
A brief history of developments
in computer vision and artificial neural networks over the last
forty years for the problem of image-based recognition. We then
present the design details of a deep learning system for endto-end unconstrained face verification/recognition.
|
|
|
An End-to-End System for Unconstrained Face Verification with Deep
Convolutional Neural Networks
Jun-Cheng Chen,
Rajeev Ranjan,
Amit Kumar,
Ching-Hui Chen,
Vishal M. Patel,
Rama Chellappa,
ICCV Workshops, 2015
/
arxiv
The end-to-end system consists of three modules for face detection, alignment
and verification and is evaluated using the newly released
IARPA Janus Benchmark A (IJB-A) dataset.
|
|
|
Unconstrained age estimation with deep convolutional neural networks
Rajeev Ranjan,
Sabrina Zhou,
Jun-Cheng Chen,
Amit Kumar,
Azadeh Alavi,
Vishal M. Patel,
Rama Chellappa,
ICCV Workshops, 2015
/
arxiv
The proposed approach exploits two insights: (1) Features obtained
from DCNN trained for face-identification task can be used
for age estimation. (2) The three-layer neural network regression method trained on Gaussian loss performs better
than traditional regression methods for apparent age estimation.
|
|
|
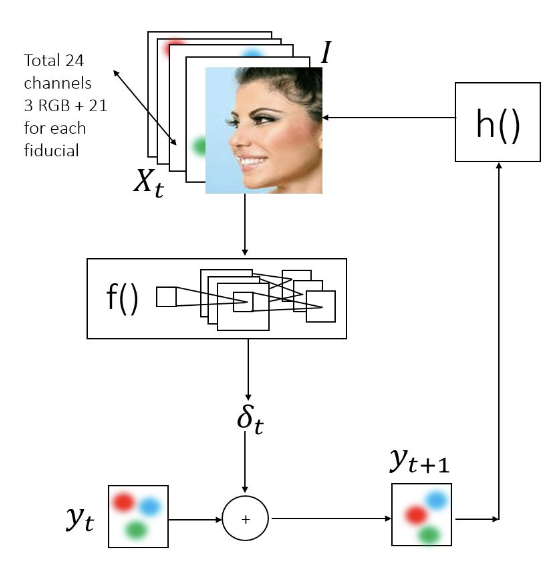
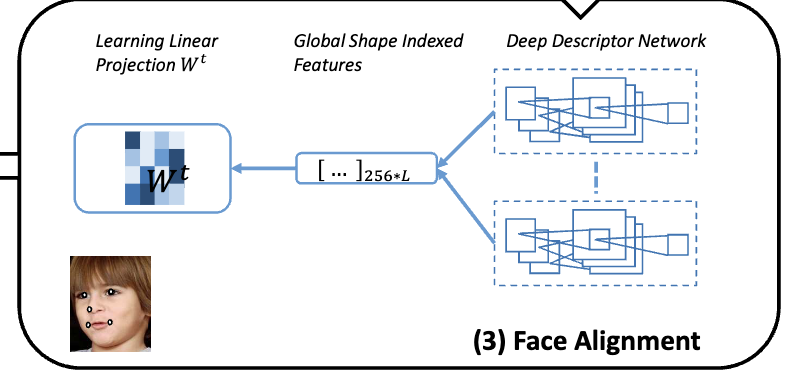
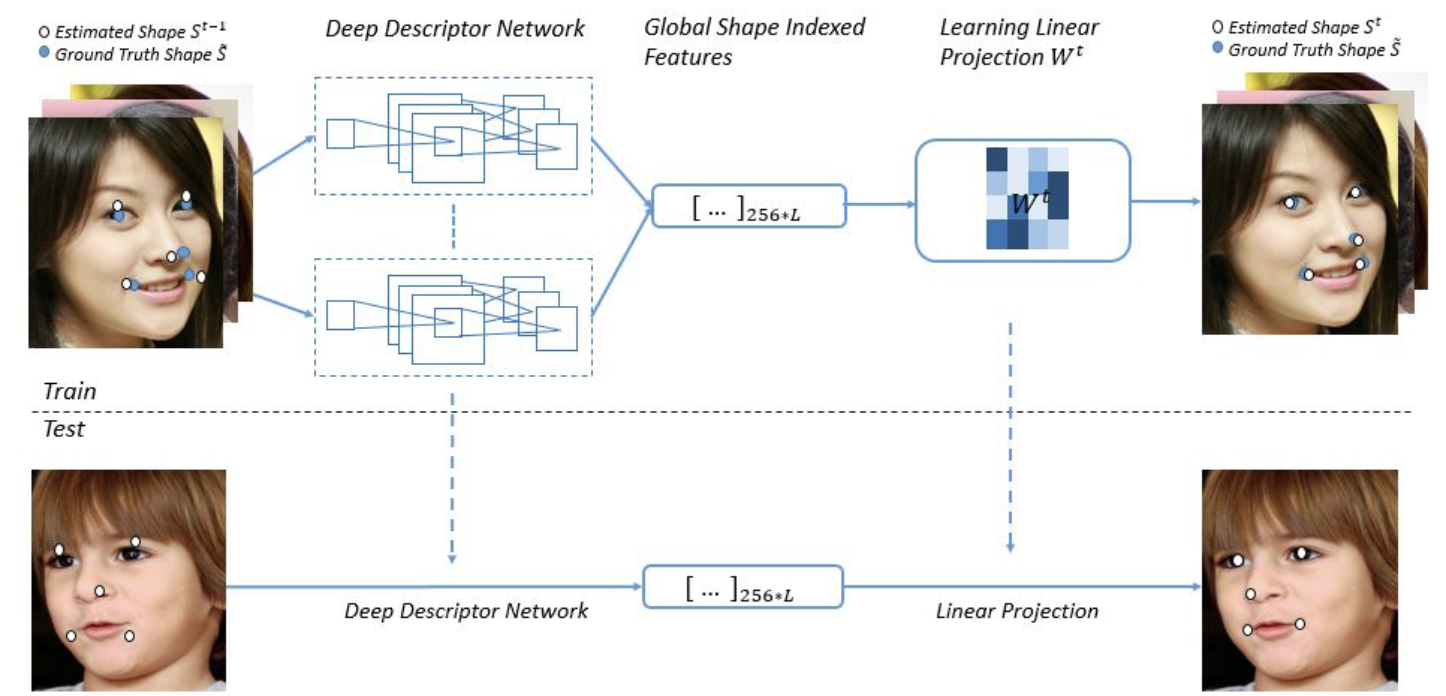
Face Alignment by Local Deep Descriptor Regression
Amit Kumar,
Rajeev Ranjan,
Vishal M. Patel,
Rama Chellappa,
Arxiv, 2015
/
arxiv
Local Deep
Descriptor Regression (LDDR) is able to localize face landmarks of varying sizes, poses and occlusions with high accuracy. Deep Descriptors presented in this paper are able
to uniquely and efficiently describe every pixel in the image
and therefore can potentially replace traditional descriptors
such as SIFT and HOG.
|
|